Estamos rodeados de comentarios acerca de cómo la inteligencia artificial IA va a cambiarlo todo. Pero la mayoría no sabe cómo afrontar esto y parece una tarea para estadísticos o por lo menos gente muy lista.
Pero creo que no hay nada más lejos de la realidad, los procesos de la inteligencia artificial son relativamente sencillos, de forma genérica.
¿Cuándo se complica esto?, cuando intentamos comprender en detalle los lenguajes aplicados (Python, R, programación del lenguaje natural, etc.), cruzados con las herramientas (visual studio, eclipse, etc. )y los entornos diseñados para manejar muchos datos y muy deprisa (balanceadores, clúster, big data, etc.).
Por eso vamos a hablar de todos los pasos necesarios, sin ver una línea de código, aplicaciones o entornos. Solo documentos y letras. En lo que el personal legal va sobrado.
El objetivo es que podamos entender y seguir conversaciones sobre IA a alto nivel. Para ello te voy a dar una definición de la IA que me gusta mucho:
La IA es como nuestra intuición, todos la tenemos por haber vivido muchas situaciones en nuestra vida, así cuando aparece una situación parecida, sabemos por impulso como salir de ella.
Entonces, tu cerebro guarda esas situaciones y extrae, de forma imperceptible para ti, una serie de claves que las definen: las personas estaban enfadadas, me miraban fijamente, nadie sonreía, estábamos en un sitio apartado, las risas eran nerviosas… o todo el mundo se abrazaba, todos sonreían, los padres besaban a sus hijos, algunas personas bailaban, etc.
Pues eso es lo mismo que vamos a hacer nosotros con los documentos, es decir, cada documento es como una situación de nuestra vida y a través de nuestra intuición sabremos si es de un tipo o de otro. Es decir, la IA no está relacionada con saber mucho y ser muy sesudo, sino con haber visto mucho y opinar por experiencia.
Lo primero de todo, necesitamos un documento, imagínate una carta a tu novio/a, una notificación, un requerimiento o la carta a los Reyes Magos.
Antes de empezar la lectura de nuestro documento
Los metadatos son datos implícitos en el documento, pero que no se ven a simple vista. Con ejemplos se entiende mejor, alguien te manda un postal, implícitamente esa postal tiene unas medidas de largo y ancho, tiene un número contable de palabras, una foto con una serie de colores, etc. Si te fijas todos los datos están en la postal y nos ayudan a definir la postal explícitamente.
La rama del conocimiento que nos ayuda a extraer los metadatos se llama procesamiento del lenguaje natural.
Empezamos a leer
Pues aquí, te voy a convertir en programador, y vamos a seguir los pasos que haría él/ella de forma conceptual.
En las librerías de los programadores, se definen varios niveles para un documento con decenas de claves en cada nivel (extensión del documento, tamaño en bytes, etc.), pero todos prueban primero si con las claves más sencillas responde a nuestras preguntas.
Paso 1
Ver en qué idioma está nuestro texto. No por obvio es menos importante.
Paso 2
Sacamos la longitud del texto. Esto es una de las cosas que mejor define un texto, si el texto tiene 250 caracteres, ya puedo descartar que no es un tweed ni un libro.
Paso 3
Extraemos las entidades, es decir, todos los sustantivos y complementos clasificados por el tipo de entidad que es. Las horas siempre tendrán una etiqueta de tiempo, los nombres propios como personas, Etc.

¿Cómo es capaz el programa de saber qué entidad corresponde con que palabra? Esto es, de nuevo, por el entrenamiento previo. Por ejemplo, respecto a los nombres de personas. En español, después de cada punto, si hay al menos tres palabras en mayúsculas, en general se tratará de un nombre propio (. Pedro Cano Martínez), si hay un sustantivo identificativo (soldado, doctor, cirujano, etc.) y luego una palabra en mayúscula generalmente será también una persona (General Rojo), etc. En cualquier caso, hay muchas aproximaciones diferentes a la detección de entidades y solo la descripción de las distintas vías, daría para otro artículo.
Paso 4
Sacamos las posiciones y las veces que se repiten cada una de las entidades. Beirut posición 0, Libano posición 8, Rusa posición 35 y posición 526,etc.
- Conclusión 1
- Solo eliminando el contenido de las entidades, es decir, no tomando en cuenta su texto literal, sino observando solo las veces que se repite y las posiciones en que lo hace, podemos detectar si el texto se ha escrito con una plantilla o no.
- Conclusión 2
- Esto, metadatos son muy interesantes, y sirven para ver si el siguiente documento, que estudiemos, está relacionado con este. Si extraemos que el Estado Islámico se repite 100 veces en un texto y en otro solamente una vez o ninguna, puedo graduar el nivel de relación entre ambos.
Desde el punto de vista legal, las entidades pueden ser los juzgados (juzgado de primera instancia, audiencia previa, etc.) los magistrados, los abogados, los procuradores, los términos jurídicos(diligencia de ordenación, edicto, sentencia, etc.) o cualquier otro tema.
Paso 5
Ver las dependencias del texto. Aquí hay que recordar cuando erais escolares y hacíais análisis sintáctico. Es decir, dividimos las frases en palabras y como cada una de las palabras se relaciona.
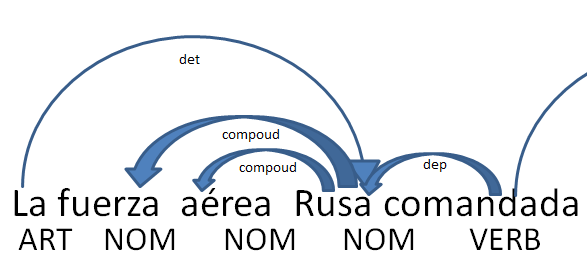
Así puedo sacar que la fuerza aérea Rusa, está relacionada dentro de este texto, a través de los verbos con:
- comandado por el general Pitilk
- ha lanzado varios misiles
- continuo avance, etc.
- Conclusión 1
- En suma puedes sacar las reglas de la relación de cada una de las entidades y saber cuáles son las dependencias entre una y otra. Así podrías hacer mapas de cómo se relacionan.
- Conclusión 2
- Revisando esas dependencias, comprobarás la importancia de esa palabra y cuál es el rol de la organización, persona o localización en el texto. Así, ciertas preguntas, se pueden resolver. ¿A quién se nombra más en el artículo?,¿Quién es aliado de Rusia?, etc.
- Extrayendo los verbos y teniendo una base de datos de sinónimos podremos comprender el rol de las diferentes entidades sin tener que leernos el texto de forma completa.
Problemas
Los principales problemas a los que nos enfrentamos en este análisis del texto siempre son las ambigüedades del lenguaje, tanto a nivel léxico, cuando una palabra tiene dos significados diferentes, a nivel sintáctico, con frases mal construidas o a nivel referencias, que no encontremos todas las entidades por no estar suficientemente bien entrenado el modelo.
Con toda esta información extraída o lo que es lo mismo, con estos metadatos, le hemos dado una cantidad de información suficiente, para que un algoritmo de machine learning haga su magia y nos:
- Clasifique los documentos por tipo
- Diferéncienos los protagonistas del texto
- Contextualícenos el relato
- Responda preguntas sobre el texto
- etc.
No responses yet